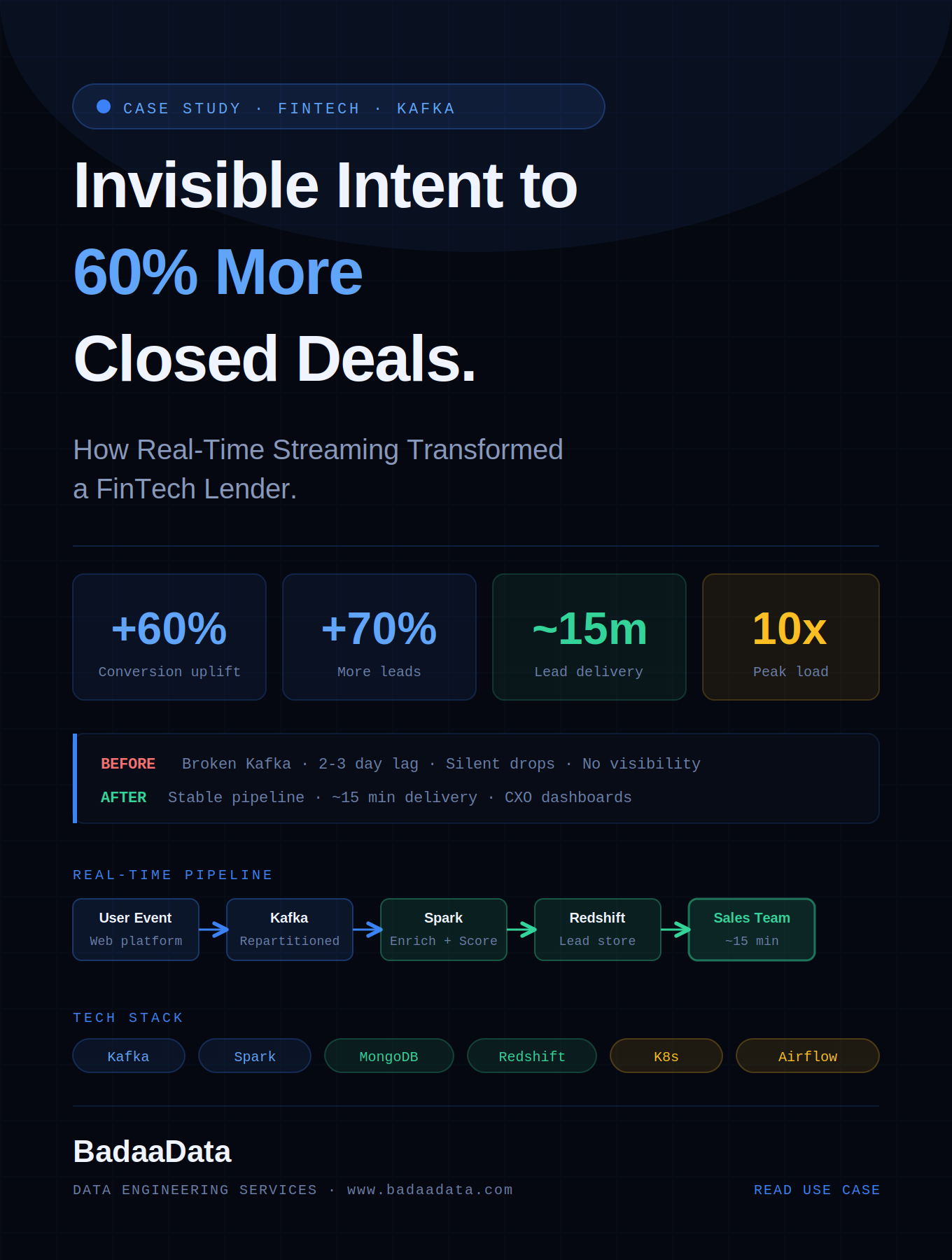
top of page


Intelligent Data Platforms Built for Real-World Use Cases
We build scalable, cloud-native, AI-ready platforms that turn complex data into actionable insights for faster decisions, efficiency, and growth.




bottom of page
We build scalable, cloud-native, AI-ready platforms that turn complex data into actionable insights for faster decisions, efficiency, and growth.